Unlocking the Future of Custom AI Development with GPT-4o: Trends and Strategies
Custom AI application development with GPT-4o represents a fundamental shift in how enterprises build intelligent systems. Rather than treating AI as a chatbot feature, forward-thinking CTOs and founders are architecting GPT-4o as the foundation for proprietary applications that solve specific, high-value business problems. Here’s the thing: the difference between a successful AI initiative and an expensive failed experiment often comes down to deliberate architecture, rigorous prompt engineering, and relentless focus on measurable outcomes.
Key Takeaway
GPT-4o’s improved reasoning, native multimodal capabilities, and lower latency make it uniquely suited for production-grade custom AI solutions. Success requires deliberate architecture, disciplined prompt engineering, and a commitment to ongoing optimization rather than a one-time implementation.
In This Article
- Why GPT-4o Matters Now for Custom AI Development
- The Core Challenge: Building Sustainable Custom AI Applications
- The Solution: GPT-4o as a Foundation for Custom AI Applications
- Key Capabilities That Enable Custom AI Applications
- Enterprise Applications Across Industries
- Building Blocks: Architecture and Prompt Engineering
- How to Get Started with GPT-4o Custom AI Development
- Common Mistakes to Avoid
- Frequently Asked Questions
Why GPT-4o Matters Now for Custom AI Development
The enterprise AI landscape shifted significantly with GPT-4o’s release. Organizations can’t rely on commodity chatbots to drive competitive advantage anymore. The real opportunity lies in building domain-specific applications that integrate seamlessly with existing systems, reduce operational friction, and unlock entirely new business capabilities.
Recent industry research tells a compelling story. Enterprise adoption of large language models has accelerated dramatically. Companies are moving beyond experimentation into production deployments that directly impact revenue and cost structure. GPT-4o addresses the exact constraints that prevented earlier models from reaching enterprise scale: cost per token, inference latency, multimodal understanding, and reasoning reliability.
“72% of enterprise technology leaders plan to embed AI into core products within the next 12 months, with LLM-based automation as the top priority.”
Gartner Enterprise AI Survey, 2024
For founders and CTOs, this timing creates urgency. Organizations that master GPT-4o-based custom application development now will establish competitive moats that are difficult to replicate. Those that delay risk being outpaced by competitors who’ve already baked AI into their product experiences, customer workflows, and internal operations.
The Core Challenge: Building Sustainable Custom AI Applications
Moving from prototype to production reveals the real complexity of enterprise AI. Many organizations launch GPT-4o pilots that show promise, only to discover that scaling to production introduces unexpected friction. Sound familiar?
Here’s what we see most often go wrong:
- Reliability at scale: Prompts that work on a handful of test cases fail unpredictably on diverse real-world data. Hallucinations, off-topic responses, and inconsistent output formatting derail applications before they launch.
- Cost management: Token consumption balloons as real-world usage exceeds assumptions. Applications that were projected to be profitable become budget drains, forcing teams to choose between sacrificing quality or killing the initiative.
- Latency constraints: Some use cases demand sub-second response times. If inference speed isn’t engineered upfront, a promising AI feature becomes too slow for production users.
- Data security: Enterprises remain cautious about sending proprietary information to cloud APIs. Without proper data governance, compliance teams may block entire initiatives regardless of capability.
- Legacy system integration: Custom AI applications don’t exist in a vacuum. They must connect to databases, existing workflows, and systems built decades ago, each with its own API quirks and constraints.
- Ongoing maintenance burden: AI applications aren’t set-and-forget. Model behavior evolves, user needs change, and competitive pressure demands constant optimization. Organizations underestimate the operational overhead of production AI.
The consequence is straightforward. Organizations that can’t navigate these challenges end up with expensive, unreliable, abandoned AI projects. Conversely, enterprises that address these challenges systematically unlock genuine competitive advantage.

The Solution: GPT-4o as a Foundation for Custom AI Applications
GPT-4o is ideally positioned as the foundation for enterprise custom AI applications because it directly addresses each pain point above. Unlike earlier models, GPT-4o was designed with production systems in mind rather than as an extension of a research project.
Here’s what makes the difference. GPT-4o’s architecture enables reliability through superior reasoning and instruction-following. The model maintains consistency across diverse inputs, understands nuanced context, and produces structured outputs suitable for automated workflows. On top of that, GPT-4o processes tokens more efficiently than predecessors, reducing operational costs by 50% or more compared to earlier versions. And because it’s natively multimodal, a single model handles text, images, and complex documents without separate vision components.
The integration story is equally important. Function calling and structured output specifications allow GPT-4o to reliably produce JSON, XML, or proprietary formats that downstream systems expect. Worth noting: the extended context window enables processing long documents, code files, and multi-turn conversations without fragmentation. The API-first design means GPT-4o integrates cleanly into existing architectures without requiring massive rewrites.
Expert Perspective
In our work with clients, the real power of GPT-4o isn’t the model itself, it’s how you architect around it. Prompt engineering discipline, retrieval-augmented generation patterns, guardrail design, and feedback loops determine whether custom AI applications succeed or fail. We’ve consistently seen teams with average models and excellent engineering outperform teams with premium models and weak execution.
When evaluating whether to build custom AI applications with GPT-4o, look for a development partner or team that demonstrates deep expertise in prompt engineering, a security-first approach to data handling, and a commitment to ongoing optimization rather than one-time delivery. Experience integrating AI into complex legacy systems matters enormously. So does the ability to articulate realistic timelines and constraints rather than overpromising on capabilities.
Key Capabilities That Enable Custom AI Applications
Understanding GPT-4o’s core capabilities helps architects make informed decisions about where to apply it. Each capability unlocks different use cases and architectural patterns.
Advanced Prompt Engineering: Few-shot learning, chain-of-thought reasoning, and role-based prompting allow you to guide GPT-4o toward specific behaviors without fine-tuning. For example, instructing the model to “think through this step-by-step before answering” dramatically improves accuracy on complex tasks. Providing 2-3 examples of desired input-output pairs teaches the model your specific format requirements without retraining.
Function Calling and Structured Outputs: GPT-4o reliably produces JSON or other structured formats, enabling programmatic workflows. A compliance automation application might ask GPT-4o to extract risk factors from regulatory documents and return results as structured JSON that downstream approval systems consume automatically. This bridges the gap between natural language understanding and deterministic business logic.
Multimodal Input (Vision): Processing images, PDFs, charts, and mixed-media documents expands use cases dramatically. Insurance companies analyze claim photos automatically. Healthcare providers extract data from handwritten patient forms. Manufacturing teams use visual inspection for quality control. This capability eliminates the need for separate vision models or manual document conversion.
Extended Context Window: GPT-4o’s 128K token context allows processing of long documents, multiple-file analysis, and complex conversation histories without truncation. A legal tech application can ingest entire contracts. A code analysis tool handles substantial repositories. Knowledge bases can be embedded directly in prompts for retrieval-augmented generation without external database calls.
Real-Time Performance: Latency matters for user-facing applications. GPT-4o’s improved inference speed makes embedding AI into customer-facing workflows feasible. Chat applications stay responsive. Search systems return augmented results quickly. Automation workflows complete in acceptable timeframes.
Enterprise Applications Across Industries
Custom AI application development with GPT-4o creates value across sectors. Understanding industry-specific applications helps contextualize the technology within your own business.
Finance and Banking
Financial institutions deploy GPT-4o for compliance document review, accelerating assessments that historically required hours of manual work. The model identifies regulatory requirements, flags discrepancies, and extracts relevant clauses from complex agreements. On top of that, anomaly detection in transaction patterns alerts fraud teams to suspicious activity. And there’s the matter of regulatory reporting automation, which reduces manual data entry and transcription errors.
Healthcare
Healthcare organizations use custom AI applications for clinical note summarization, reducing documentation burden on clinicians. Patient intake automation extracts relevant medical history from unstructured patient communications. Medical coding assistance recommends appropriate diagnostic codes based on clinical documentation. That said, it’s critical to maintain clear boundaries where clinician review remains mandatory, not optional. AI assists but doesn’t replace clinical judgment.
Manufacturing and Supply Chain
Manufacturers leverage GPT-4o’s multimodal capabilities for visual inspection and quality control. Predictive maintenance recommendations anticipate equipment failures before they occur. Supplier communication automation handles routine inquiries and order management. Logistics optimization suggests routing and scheduling improvements based on historical patterns and constraints.
SaaS and Software
Software companies embed GPT-4o into customer support platforms that understand context from entire conversation histories and customer data. Code analysis tools help developers identify bugs, suggest improvements, and generate documentation. Feature request triage systems automatically categorize customer feedback and identify high-priority patterns. Real-time performance enables these systems to run within user interactions rather than as batch processes.
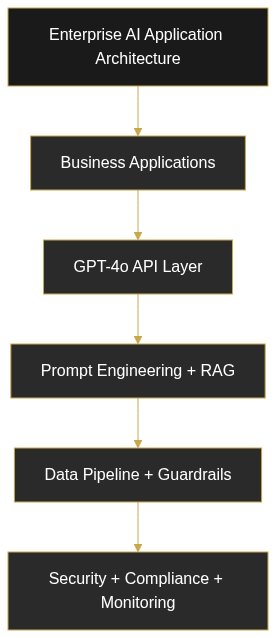
Building Blocks: Architecture and Prompt Engineering
Successful custom AI applications follow a consistent architectural pattern. Understanding this pattern helps teams avoid common mistakes and accelerate time to production.
Define Clear Intent and Scope
Start by explicitly stating what specific business problem the AI application solves. Articulate where human judgment remains essential and non-negotiable. Identify failure modes and their business consequences. If your application flags compliance violations incorrectly, what’s the cost? If it misses a violation, what’s the liability? These conversations inform guardrail design and testing rigor.
Design for Reliability Through Prompting
Assign the model a specific persona or role. Instead of asking “summarize this contract”, try “You’re a senior contract attorney with 20 years of M&A experience. Summarize this contract, flagging any unusual terms.” Explicitly specify output format and validation rules. Use chain-of-thought reasoning for complex tasks: “Think through this problem step by step before providing your final answer.” Provide 2-3 examples of desired behavior through few-shot prompting.
Integrate Data and Context (RAG Pattern)
Retrieval-augmented generation is critical for domain-specific accuracy. Rather than training or fine-tuning models with proprietary data, embed relevant context directly into prompts. Structure knowledge bases for effective retrieval. Balance real-time data freshness against cost and latency constraints. A customer support application might retrieve relevant help articles and recent order history before prompting GPT-4o to respond to a customer inquiry.
Build Guardrails and Monitoring
Implement output validation to filter responses that don’t meet quality standards. Track cost and latency metrics continuously. Establish performance baselines and alert when applications drift from expected behavior. Create feedback loops so users can flag incorrect responses, feeding training data for prompt refinement. Monitor for emerging failure modes that didn’t appear in initial testing.
How to Get Started with GPT-4o Custom AI Development
Building a custom AI application follows a staged approach that reduces risk and validates assumptions early.
- Identify High-Impact Use Cases: Map processes where AI can reduce cost, improve speed, or unlock new capabilities. Create a prioritized list of 2-3 pilot applications with clear success metrics. This produces a focused roadmap rather than attempting too many initiatives simultaneously.
- Prototype with Prompt Engineering: Build initial prompts, test with sample data, and iterate on clarity and output quality. This demonstrates feasibility and quantifies business value before significant engineering investment. A successful prototype might process sample documents with 90%+ accuracy in 2-3 hours of prompt refinement work.
- Design for Integration and Scale: Plan API architecture, data flows, error handling, and user feedback loops. This produces a technical specification ready for development and clarifies dependencies on existing systems. Architectural decisions made here prevent costly rewrites later.
- Implement Monitoring and Optimization: Set up cost tracking, latency measurement, output quality metrics, and user satisfaction signals. This establishes an operational baseline and identifies optimization opportunities. Production applications reveal performance patterns that testing never surfaces.
- Iterate Based on Real-World Performance: Collect feedback continuously, retrain prompts based on failure cases, and explore fine-tuning if specific domains justify it. This transforms applications from static to continuously improving systems. The feedback loop is where most value accumulates over time.
Common Mistakes to Avoid
Organizations building custom AI applications commonly encounter preventable problems. Learning from others’ mistakes accelerates your path to production success.
Treating prompt engineering as a one-time task is the first critical mistake. Prompts require iteration as you encounter real-world data variation, changing business requirements, and new use cases. Here’s the thing most guides won’t tell you: underestimating the importance of guardrails and validation leaves applications vulnerable to embarrassing failures or compliance violations. Additionally, ignoring cost implications of context window and token usage at scale creates budget surprises. Deploying without a feedback mechanism or monitoring strategy prevents learning from production behavior.
Never assume a single prompt works across all user segments or data types. Different data distributions, languages, or user sophistication levels often require prompt variation. Additionally, neglecting data security and compliance considerations from day one creates retroactive problems that are expensive to fix. Organizations that discover privacy issues after production launch face remediation costs far exceeding upfront security investments.
Finally, avoid the mentality that AI applications replace domain expertise. Your fraud detection system needs fraudsters and forensic analysts involved in design and review. Your medical coding assistant needs coders and physicians guiding its development. Your contract review tool needs attorneys validating its output. AI enhances expert judgment but shouldn’t replace it entirely.
Frequently Asked Questions
How does GPT-4o compare to GPT-4 Turbo for custom AI applications?
GPT-4o is faster, more cost-efficient, and natively multimodal, making it the superior choice for most enterprise applications where latency and cost matter. GPT-4 Turbo may be preferred for reasoning-heavy tasks with very long context needs, though GPT-4o has closed this gap significantly. For custom AI application development specifically, GPT-4o is the recommended foundation today.
What’s the role of fine-tuning versus prompt engineering in custom AI applications?
Start with prompt engineering and retrieval-augmented generation because they’re faster to iterate and don’t require extensive labeled datasets. Fine-tuning becomes valuable when you’ve got domain-specific patterns, consistent task structures, or cost and latency constraints that prompt engineering alone can’t solve. However, most organizations achieve production-quality custom AI applications through disciplined prompt engineering and RAG before exploring fine-tuning.
How do we ensure data security when using GPT-4o APIs for proprietary data?
Implement data anonymization before sending information to APIs, use OpenAI’s API data privacy terms that specify data isn’t used for model training, encrypt information in transit and at rest, and maintain strict access controls around API keys. For highly sensitive data, consult with security specialists about on-premise LLM alternatives or advanced architectural patterns like local embeddings with cloud completion.
What metrics should we track to measure custom AI application success?
Define baseline metrics including cost per transaction, inference latency, output quality or accuracy, and user adoption rates. Track token efficiency to identify optimization opportunities. Establish success benchmarks during the pilot phase and continuously monitor production performance. Common metrics include accuracy against human review, cost per completion, average response time, and user satisfaction scores.
How often should we update prompts and models as GPT-4o evolves?
Monitor OpenAI releases and significant model updates quarterly. Test new versions in staging environments before production rollout. Refresh prompts when you observe performance gains, cost reductions, or when business requirements change. Most organizations refresh production prompts every 6-12 months as new techniques emerge and operational data reveals optimization opportunities.
Ready to Build Proprietary AI Applications?
Custom AI application development with GPT-4o isn’t theoretical anymore. Forward-thinking enterprises across industries are already deploying GPT-4o-powered solutions that reduce costs, accelerate workflows, and unlock new revenue streams. The technical foundation is proven. The question is whether your organization will lead this shift or follow competitors who move faster.
Organizations building custom AI applications in cities like London, and Singapore are discovering that success requires more than off-the-shelf solutions. It demands deliberate architecture, prompt engineering discipline, security-first implementation, and ongoing optimization from teams with deep GPT-4o expertise.
Transform Your Enterprise with GPT-4o Applications
Expert guidance on custom AI application architecture, prompt engineering strategy, and production deployment helps you move from experimentation to competitive advantage. Our team combines deep GPT-4o expertise with security, architecture, and integration experience across enterprise systems.